概要
機械学習を扱う装置を作る際、学習モデルをlobeで作っているのですが、マスク処理を行った画像の判定論理が気になったので調べてみました。やったこと
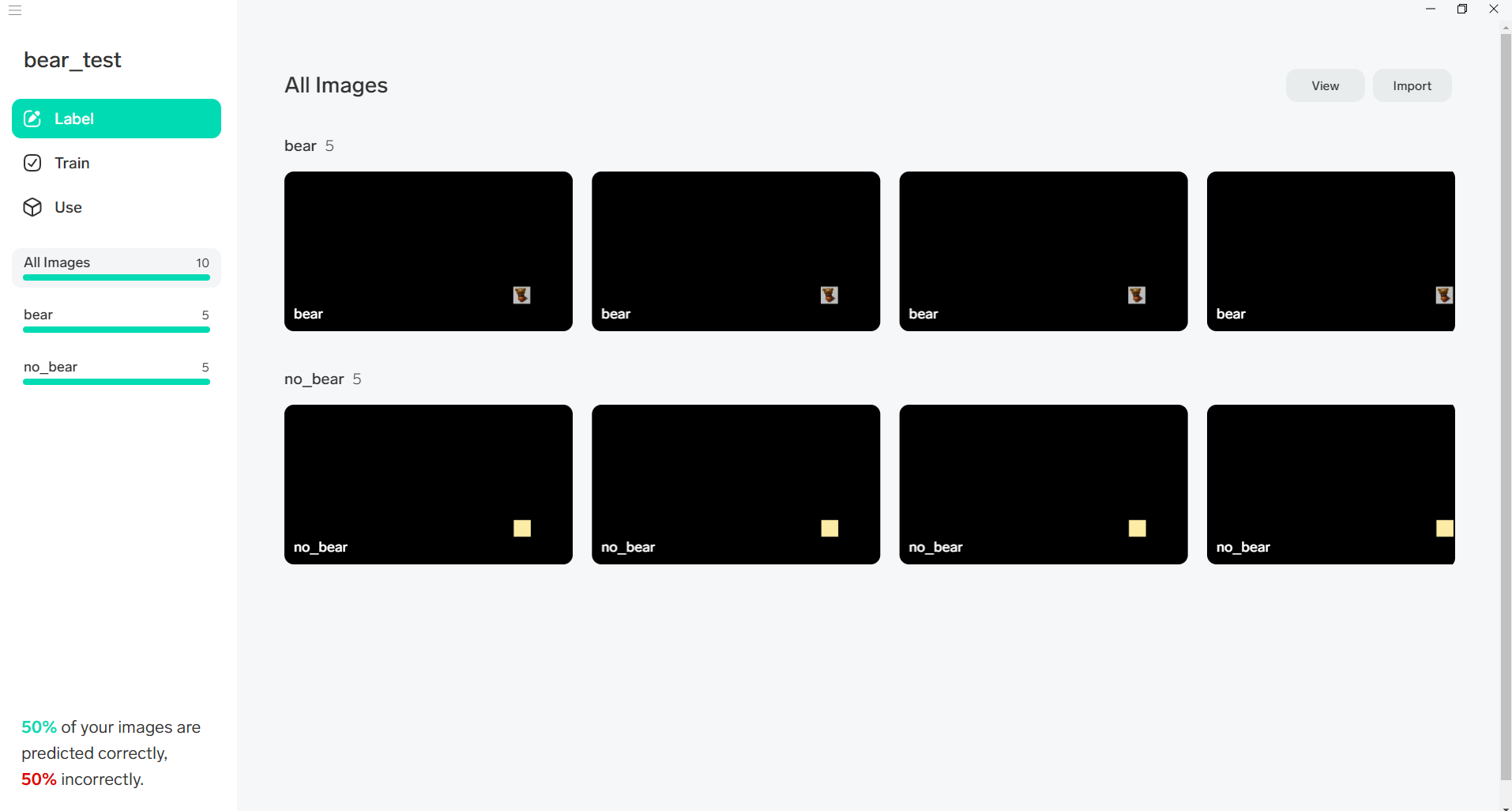
- 右下にクマがいる画像とクマがいない画像を5枚ずつ登録
- その状態で左上にクマがいる画像を判定できるか →期待は「bear」だったが、「no_bear」だった。
- 判定できるようになるまでに何枚の画像を登録する必要がるのか →左上にクマがいる画像を追加で11枚登録したら、「bear」と認識するようになった。
- 判定できるようになったとき、右下に画像がある情報を判定できるか →右下にクマがいない画像を判定したところ、期待は「no_bear」だったが「bear」と判定された。



結論
- マスク処理を行う場合は同じ場所をマスク処理したもので学習モデルを作ったほうが良い。
- 判定に使うための情報はラベルごとに同じ枚数のデータを学習させたほうが良い。
0 件のコメント:
コメントを投稿